8 Database Design Best Practices That Actually Matter
Stop guessing. We break down 8 essential database design best practices with real-world examples to help you build scalable, high-performance systems.

Isabelle Fahey
Posted on 28 August 2025


Stop guessing. We break down 8 essential database design best practices with real-world examples to help you build scalable, high-performance systems.
Let’s be honest. Most 'best practice' guides are written by people who’ve never felt the cold sweat of a production database grinding to a halt at 3 AM. They’re full of generic advice like 'plan ahead' and 'be consistent.' Thanks, Captain Obvious. Building a solid database isn't about following a sterile checklist; it's about making smart, opinionated decisions that prevent future chaos. I’ve seen enough spaghetti schemas and unindexed tables to last a lifetime, and I’m here to save you from that fate.
This isn't your professor's textbook on relational algebra. This is a battle-tested list of database design best practices forged in the fires of late-night deployments and performance-tuning death marches. We're skipping the fluff and getting straight to the stuff that separates a robust, scalable system from a ticking time bomb you'll have to pay someone a small fortune to fix later. We’ll cover everything from normalization and indexing to security and disaster recovery, giving you actionable steps instead of vague theory. So, grab a coffee. Let’s talk about how to build a database that won't make you want to mortgage your office ping-pong table to rewrite it in six months.
Table of Contents
If your database tables look like a disorganized spreadsheet from the abyss, normalization is the cleanup crew you desperately need. It’s the process of organizing your database to reduce data redundancy and improve data integrity. Think of it as the ultimate decluttering method for your data, preventing the digital equivalent of hoarding duplicate information.
The core idea is to break down large, unwieldy tables into smaller, more manageable ones and link them using relationships. This systematic approach, pioneered by Edgar F. Codd, eliminates anomalies that occur during data updates, insertions, and deletions. Getting this right is a cornerstone of solid database design best practices, saving you from a world of future headaches.
Imagine an e-commerce system where customer, order, and product details are crammed into a single table. A customer updates their shipping address? Hope you enjoy finding and changing it in every single order row they've ever placed. Miss one, and you’ve just created conflicting data. Normalization solves this by creating separate Customers, Orders, and Products tables, ensuring each piece of information lives in only one place.
The process follows a series of guidelines called "normal forms," each addressing a specific type of redundancy.
This concept map breaks down the first three stages of normalization, showing the progression from eliminating repeating groups to removing more complex dependencies.
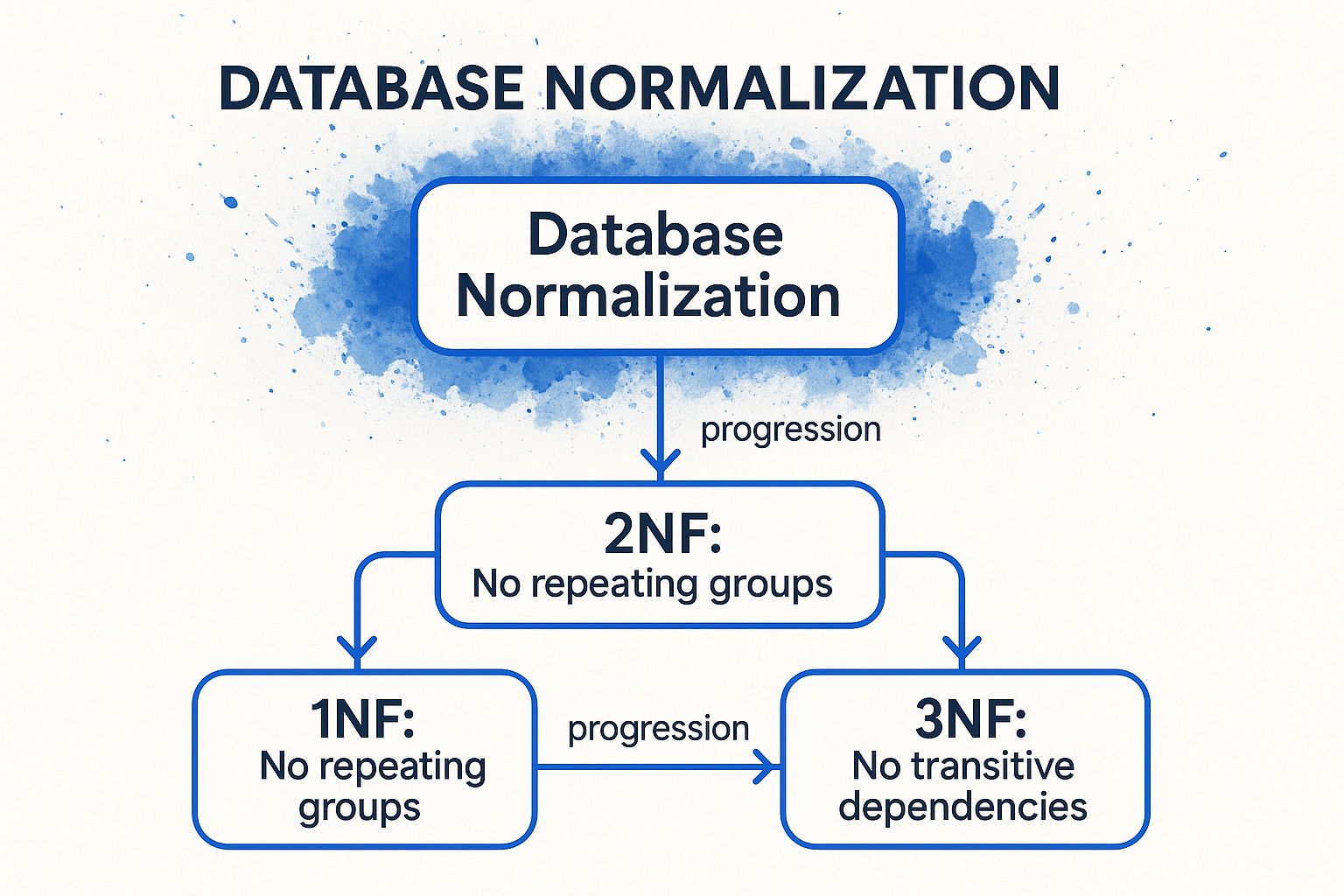
As the infographic illustrates, each normal form builds upon the last, systematically refining your data structure to ensure information is stored logically and efficiently.
While there are several normal forms (up to 6NF and beyond), most real-world applications find a sweet spot with the third.
If your table rows had résumés, the primary key would be the one thing that makes each one uniquely hireable. It’s the non-negotiable, one-of-a-kind identifier for every single record in a table. Without a solid primary key strategy, your database is just a crowd of records where everyone looks the same, making it impossible to reliably find, update, or connect anything.
The core purpose of a primary key is to enforce entity integrity, guaranteeing that no two rows are the same and that no identifier is ever null. This isn't just a nice-to-have feature; it’s the foundational mechanism that allows for stable relationships between tables, a critical part of any list of database design best practices. Mess this up, and you’re basically building a house with no foundation.
Imagine you’re running an inventory system. You have two products named "Classic T-Shirt," both in size medium but with different designs. If you use the product name as an identifier, how do you tell them apart? A well-chosen primary key, like a unique Product SKU or an auto-generated ID, solves this instantly. It gives you a stable, unique handle for every item, regardless of its other attributes.
This unique identifier becomes the hook for other tables. Your Orders table doesn't need to store the product's name, size, and color; it just needs the ProductID. This creates clean, efficient relationships that are fast to query and easy to maintain.
Picking the right primary key is more art than science, but sticking to a few rules will save you from a world of hurt.
IDENTITY or AUTO_INCREMENT) or UUIDs. Relying on "natural keys" like an email address or a Social Security Number is a ticking time bomb. What happens when someone changes their email? Your entire web of relationships breaks.INT versus a long VARCHAR) means smaller indexes, less disk space, and faster joins. Once set, a primary key's value should never, ever change.If your database queries are moving at a glacial pace, a poor indexing strategy is the likely culprit. Indexing is like creating a hyper-efficient table of contents for your database. Instead of a full-table scan (reading every single row), the database engine uses the index to jump directly to the data it needs, transforming a painstaking search into a lightning-fast lookup.
A proper indexing strategy is one of the most impactful database design best practices you can implement for performance. Getting it wrong means sluggish applications and frustrated users. Getting it right feels like upgrading your server's hardware for free. It’s the art of speeding up data retrieval without bogging down data modification operations like inserts, updates, and deletes.

Imagine an e-commerce site where users filter products by category and price. Without indexes, the database would have to sift through every single product for every search. Now, picture an index on the category and price columns. The database can now instantly find all products matching the criteria, delivering results in milliseconds instead of seconds.
This concept extends to any high-traffic system. A social media app uses indexes to quickly find user profiles, a CRM relies on them to pull up customer records by email, and a financial platform needs them to fetch transaction histories. Indexes are the unsung heroes of responsive applications.
Don't just slap an index on every column and call it a day, that’s a recipe for disaster. Effective indexing is about precision and strategy.
WHERE, JOIN, and ORDER BY clauses. These are your prime candidates for indexing.If you're using a BIGINT to store a user's age or TEXT for a two-letter country code, you’re basically renting a mansion to store a shoebox. Data type optimization is the art of choosing the smallest, most efficient data type that can reliably hold your information. It’s a foundational database design best practice that directly impacts storage costs, query speed, and data integrity.
Think of it as digital discipline. Assigning oversized data types is like packing your database with junk, making it bloated, slow, and expensive to maintain. By being precise, you ensure your database runs lean, keeping performance high and preventing nonsensical data from ever entering your columns. Getting this right means your database won't buckle under its own weight as you scale.
Imagine a status column in an orders table, storing values like 'shipped', 'pending', or 'delivered'. Storing these as strings (VARCHAR) is inefficient. If you have millions of orders, you're wasting space and forcing the database to perform slower string comparisons. A better approach is using a TINYINT to represent these states (e.g., 1 for pending, 2 for shipped), which uses just one byte per row.
This principle applies everywhere. Using DECIMAL for financial data prevents the floating-point rounding errors that FLOAT can introduce, ensuring your balance sheets actually balance. Likewise, choosing DATE instead of DATETIME when you don't need the time component saves bytes on every single row, which adds up significantly over millions of records.
Don't just accept the default data types your framework suggests; be deliberate and make informed choices.
TINYINT is perfect for flags or statuses (0-255). Don't use INT when SMALLINT will do. For currency, always use DECIMAL or NUMERIC for exact precision.TEXT or NVARCHAR(MAX) types unless you genuinely need to store a novel. For columns like usernames, email addresses, or postal codes, use VARCHAR with a sensible maximum length. This improves indexing and memory usage.DATE, DATETIME, or TIMESTAMP types, not as strings or integers. This enables powerful date-based calculations and ensures data validity without messy conversions.If your database allows an order to exist without a customer, you’re not running a business; you’re managing a digital ghost town. Referential integrity is the set of rules that prevents these kinds of phantom records, ensuring relationships between your tables actually make sense. It’s the database’s way of enforcing common-sense logic, so you don’t have to clean up the mess later.
Think of it as the uncompromising bouncer for your data. Using constraints like foreign keys, you ensure that every piece of related data has a valid, existing counterpart. This fundamental practice within database design best practices prevents orphaned records, enforces business rules at the lowest level, and keeps your data ecosystem from devolving into chaos.
Imagine a library system where a user can borrow a book that doesn't exist or an author can be linked to a deleted publication. Without referential integrity, these scenarios are not just possible; they're inevitable. Constraints act as guardrails, automatically preventing these invalid operations. A foreign key constraint, for instance, would stop you from deleting a Customer record if they still have outstanding Orders.
This is about making your database schema self-enforcing. Instead of relying on application logic to prevent bad data (which can have bugs or be bypassed), you build the rules directly into the database foundation. This guarantees consistency, no matter how the data is accessed.
Don't just add foreign keys and call it a day. Being strategic with your constraints is key to a robust and reliable system.
ON DELETE CASCADE for data that is truly dependent, like deleting line items when an order is deleted. For critical relationships, ON DELETE RESTRICT is your best friend, preventing accidental deletion of foundational records.CHECK: Use CHECK constraints to enforce rules within a column or row, such as ensuring an order_status can only be one of a few predefined values ('pending', 'shipped', 'delivered').UNIQUE Constraints: When you need to guarantee uniqueness but don't need the indexing performance benefits, a UNIQUE constraint is more explicit about its purpose than a unique index. It clearly signals an integrity rule.If you think a firewall is all you need to protect your data, you’re essentially leaving your vault wide open with a "please rob us" sign. Database security isn't just a feature; it's a non-negotiable pact to protect your most valuable asset from unauthorized access, corruption, or theft. It involves a layered strategy of authentication, authorization, and encryption to keep sensitive information locked down.
The core idea is to control who can see and do what within your database. This systematic approach, guided by frameworks like NIST and ISO 27001, ensures that data confidentiality and integrity are maintained. Getting this right is a critical part of modern database design best practices, saving you from catastrophic breaches, regulatory fines, and the distinct honor of appearing on the evening news.
Imagine a healthcare application where every user, from a receptionist to a brain surgeon, has the same level of access. A single compromised account could expose every patient's medical history, a clear HIPAA violation with devastating consequences. A proper security model solves this by enforcing the Principle of Least Privilege, granting users only the permissions absolutely necessary to perform their jobs.
This involves defining specific roles, encrypting sensitive data like patient records both at rest and in transit, and maintaining detailed audit logs to track all activity. For instance, financial institutions rely on these controls to meet PCI-DSS compliance and protect credit card data.
Don’t wait for a breach to take security seriously. Building a secure foundation from the start is infinitely easier than cleaning up a mess.
If your database responds with the speed of a sloth on tranquilizers, it’s time to talk about performance. A brilliantly designed schema means nothing if your queries take a coffee break every time they run. Performance monitoring and query optimization is the ongoing process of keeping your database in peak condition, ensuring it can handle the demands of your application without breaking a sweat.
Think of it as being a Formula 1 pit crew for your data. You don’t just build a fast car; you constantly track its vitals, identify bottlenecks, and make real-time adjustments to keep it winning. Neglecting this crucial practice in your database design best practices is like building a skyscraper on a foundation of quicksand; it’s not a matter of if it will crumble, but when.
Imagine an e-commerce platform during a Black Friday sale. Suddenly, checkout queries slow to a crawl, and users start abandoning their carts. Without monitoring, you're flying blind, guessing what’s wrong. With a proper monitoring setup, you’d instantly see that a poorly written query is scanning an entire multi-million row table, hogging CPU and causing a system-wide bottleneck.
This proactive approach involves using tools to analyze query execution plans, track resource usage (CPU, memory, I/O), and identify which operations are the most expensive. By finding and fixing these performance hogs before they become critical failures, you ensure your application remains fast, responsive, and reliable, even under heavy load.
Getting started with performance tuning doesn't require a Ph.D. in database internals. It's about being systematic and focusing on what matters most.
If your data only exists in one place, you're not managing a database; you're babysitting a time bomb. Backup and disaster recovery planning is the non-negotiable insurance policy against every nightmare scenario, from a clumsy intern dropping the main production table to your data center being hit by a rogue meteor. It's about ensuring you can bring your data back from the dead, quickly and reliably.
This isn't just about making copies; it's a comprehensive strategy for business continuity. A solid plan means you've thought through how much data you can afford to lose (Recovery Point Objective) and how long you can afford to be down (Recovery Time Objective). Getting this wrong is one of the fastest ways to turn a minor hiccup into an extinction-level event for your business.

As this process shows, a layered defense is the only real defense. Relying on a single backup method is like locking your front door but leaving all the windows wide open.
A great backup plan isn't something you set and forget. It's a living process that needs to be as dynamic as your data itself. Financial institutions, for instance, use real-time replication across multiple data centers because even a few seconds of data loss is catastrophic. This level of planning, similar to the iterative nature of agile development best practices on clouddevs.com, ensures resilience is built in, not bolted on.
The goal is to make recovery so routine it's boring. When a real disaster strikes, you want your team executing a well-rehearsed, documented plan, not frantically improvising.
Don't wait for a crisis to find out your backups are corrupted or your recovery script has a typo.
| Topic | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Database Normalization | Moderate to high; requires design expertise | Moderate; involves schema redesign | Minimized data redundancy, improved integrity | Complex relational databases needing consistency | Reduces redundancy, prevents anomalies |
| Primary Key Design and Selection | Low to moderate; mostly design decision | Low; minimal additional resources | Ensures unique row identification, indexing | All relational tables | Guarantees uniqueness, improves query speed |
| Proper Indexing Strategy | Moderate; requires planning and monitoring | Moderate to high; impacts storage and maintenance | Faster query execution, improved filtering | Read-heavy systems with complex queries | Dramatic SELECT speed-up, supports constraints |
| Data Type Optimization | Low to moderate; requires data analysis | Low; no extra hardware needed | Reduced storage, better performance | Systems with varied data requiring efficiency | Saves space, improves query and cache efficiency |
| Referential Integrity and Constraints | Moderate; careful schema design and maintenance | Low to moderate; constraint checks add overhead | Maintains consistent relationships | Systems with complex table relationships | Ensures data consistency, reduces app validation |
| Database Security and Access Control | High; involves authentication and encryption setup | Moderate to high; monitoring and encryption increase overhead | Protected data and compliance | Sensitive data environments, regulated industries | Strong data protection, regulatory compliance |
| Performance Monitoring and Query Optimization | High; requires specialized tools and ongoing effort | Moderate to high; tooling and expert resources | Optimized query performance, reduced bottlenecks | Large scale or high traffic systems | Proactive tuning, resource cost savings |
| Backup and Disaster Recovery Planning | Moderate to high; requires infrastructure and planning | High; storage and redundant systems needed | Reliable data recovery and business continuity | Critical systems needing data protection | Minimizes data loss, supports recovery SLAs |
There you have it, the playbook for avoiding a database that looks like it was designed by a committee on a Friday afternoon. We’ve walked through the pillars of robust data architecture, from the elegant simplicity of normalization to the non-negotiable necessity of a rock-solid backup plan. Getting these database design best practices right isn’t just about following rules; it's the cheapest, most effective performance and scalability insurance you can buy.
Each one of these principles is a decision point. Do you opt for a VARCHAR(255) for everything because it's "easy," or do you choose the right data types and save yourself from bloated tables and sluggish queries? Do you skip indexing to ship a feature faster, knowing you're just kicking the performance can down the road? These aren't just technical choices; they are business decisions with long-term consequences.
The pressure to ship yesterday is real. It’s tempting to cut corners and tell yourself you'll fix it later. But "later" usually means after a critical outage, a security breach, or when your lead engineer quits because they’re tired of fighting a system that fights back. A well-designed database is your silent co-founder, the unsung hero that makes every new feature faster to build, every query more efficient, and every new hire's onboarding smoother.
Think of it this way: a solid foundation doesn't just hold the building up; it makes adding a new floor possible. A shaky one makes you terrified of a strong gust of wind. Your database is that foundation.
Don't just bookmark this article and forget about it. Turn these insights into action.
Mastering these database design best practices is what separates the teams that scale from the ones that scramble. It’s the difference between confident growth and a constant, low-grade panic every time user traffic spikes. The architecture you lay down today directly determines the limits of your success tomorrow. Build a fortress.

Learn the key interview questions for engineering manager roles. Prepare for behavioral, technical, and leadership queries to hire top talent.

Discover proven resource allocation optimization strategies to boost efficiency and reduce burnout. Maximize your team's productivity and impact today.

Stop burning cash on software development. Learn battle-tested strategies to reduce software development costs from a founder who has seen it all.

